This document explains the architecture of Runbook. This guide is useful for Developers looking to contribute to Runbook as well as anyone else interested in the setup and design.
Principles of Runbook's architecture
Before explaining the components of the Runbook application it is important to cover the key principles that govern architecture decisions for Runbook. You can think of these as Runbook's rules of architecture.
Be highly available
While Runbook currently does not offer an SLA for availability to users, high availability is a key component of its design. Our users rely on Runbook to resolve issues automatically for them during their own outages, so if our monitoring service is unavailable to them while they are having an outage we are not going to continue having their trust.
Our monitoring service is more important than our dashboard
While this might sound counter-intuitive to our first principle, high availability sometimes means we must make difficult choices. If a design must choose between the availability and function of the user-facing web interface versus the availability and function of our monitoring service, the monitoring service should come first. Obviously, every effort should be made to maintain the availability of the web interface, but this is secondary in importance to our monitoring system. An example of this decision can be seen in the way our Reaction processes handle database downtime.
Each component must be able to scale
When designing and developing for Runbook it is important to think about the scale of the changes you're making. Can these changes scale to thousands of users with thousands of Monitors? Could Facebook or Google use our product out of the box? With this in mind, we tend to keep Monitors and Reactions as stateless as possible and only utilize our Redis Cache and RethinkDB database for what is required to perform the action. However, we do sometimes need to store data for Monitors and Reaction states. When necessary, that data is stored in Redis with a timeout value. This approach ensures that even if we need stored data, it is only the latest data we need and will be purged automatically to avoid data bloat.
Encrypt network communications between servers
While the application itself does not always encrypt communications (due to the complexity of encryption and key exchanges), the traffic itself is encrypted when it leaves the server. Runbook heavily utilizes stunnel. For example, our data persistence layers do not inherently support encryption, so all client and server communications are tunneled through stunnel.
Do not assume any network is trusted
The encryption methods above are even used for servers that exist in the same datacenter. DigitalOcean and many other providers generally offer a private network. However, this network should not be assumed as private since other customers of DigitalOcean also have access to it.
Keep it simple and stupid
This can be a difficult principle to follow when developing a complicated system such as Runbook, but we strive for simplicity. Sometimes, a developer may find themselves faced with a decision about whether to build a component with simplicity or functionality in mind. It is often better to design with simplicity, as simplicity will allow for a greater addition of functionality later. In addition, simplicity makes the production system easier to manage and easier to manage automatically.
Be modular
The Runbook application is designed to be modular as possible, and places where it is not are undergoing development to improve their modularity. By keeping the application modular we are able to add features easier and faster. This also has the benefit that new developers are able to add functionality without knowing and understanding the full application.
Eat your own dog food
Runbook is a service that allows users to build environments that require minimal human interaction, especially for incidents. Runbook heavily relies on its own application to provide a "self healing" environment. This is part of the reason that the monitoring service must be kept available above the web interface. When the web interface goes down, the monitoring service can correct it. Runbook has no on-call support, and this requires Runbook itself to be its own most advanced user.
Components
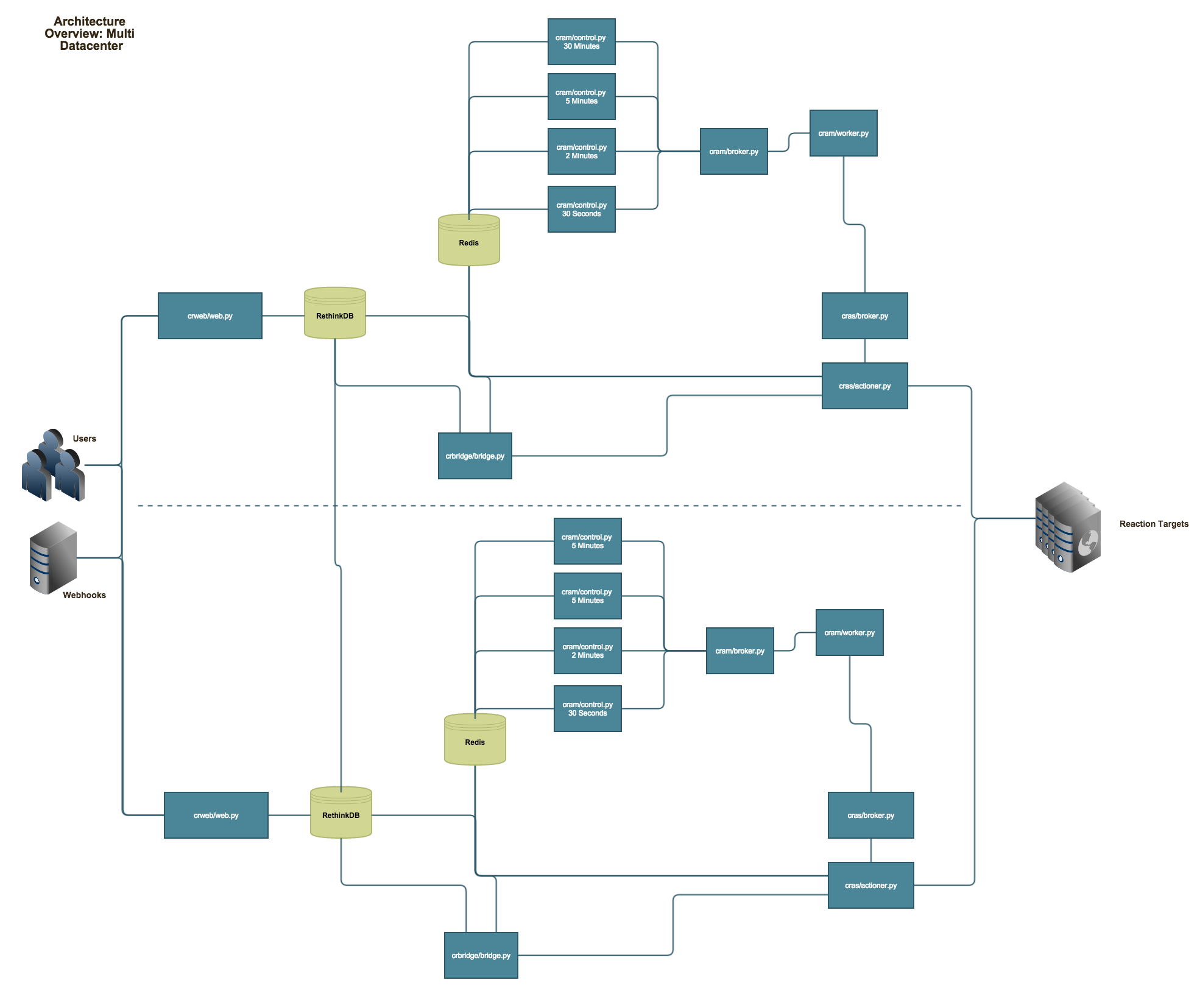
Runbook currently has 4 major application components, monitors, actions, bridge and web. Each component is designed to be independently scalable. One component may be scaled without requiring other components to meet the same scalability.
Note: The name CloudRoutes appears several times within this document. This is because CloudRoutes was the original name of the Runbook product.
WEB - CloudRoutes Web Application
The CloudRoutes Web Application is the easiest component to understand. This is a simple Flask web application that serves as the user interface for creating Monitors and Reactions, managing a users subscription, and a dashboard for the current state of Monitors. In addition, the WEB component also receives and processes Webhook Monitors. These are Monitors where services such as Datadog, PaperTrail, or Travis-CI notify Runbook of Monitor status.
The main process for this application is web.py. In production, this process is managed by the uWSGI application server, which is launched via supervisord. The supervisord service will restart the uWSGI processes should they fail or be stopped abnormally.
In front of the uWSGI process is the nginx webserver. This webserver is used to serve static files and forward non-static requests back to the uWSGI service. This is designed to scale as needed. It is possible to run more uWSGI back-end application servers than nginx front-end webservers. At the moment, these are in a one-to-one ratio but could be changed easily.
Persistence
WEB uses RethinkDB as its back-end database system. RethinkDB is a highly scalable JSON document database. We chose this database for several reasons.
- Provides out of the box synchronous replication
- Queries are automatically parallelized and distributed amongst multiple nodes
- Allows for scaling at both a local datacenter and cross datacenter level
BRIDGE - CloudRoutes Bridge
The CloudRoutes Bridge application is designed to bridge the gap between the web front-end and the monitoring and reacting back-end systems. When Monitors and Reactions are created, the WEB process stores them into the monitors or reactions tables within RethinkDB. The WEB process also places a create, edit, or delete entry into the dc#queue tables within the database. The bridge/bridge.py process is constantly reading from the dc#queue table and processing the entries placed within those tables.
Each dc#queue table is unique for each data center Runbook runs from. In production today, Runbook runs out of only 2 data centers. This means that there are currently two dc#queue tables: dc1queue and dc2queue. Since the WEB process itself does not interact with the back-end monitors the dc#queue tables are used to relay tasks to the back-end systems. It is the bridge system's responsibility to process those tasks.
When the bridge process receives a create task it will read the Monitor or Reaction configuration from the database entry and store that data in that data center's local Redis instance. Each datacenter or "monitoring zone" within the Runbook environment has its own local Redis server. This Redis server is not replicated to any other data centers and is simply there to serve as a local cache for Monitors and Reactions running from that data center.
Note: If an issue was to occur where a local Redis instance was destroyed and unrecoverable, a new Redis server can be repopulated using the bridge/mgmtscripts/rebuild_Redis.py script. This script reads from RethinkDB and creates edit requests within each data center's dc#queue. This will cause a re-population of each Redis instance in each data center. This is a benign process as RethinkDB is designed to be the source of truth regarding Monitor and Reaction configurations.
In addition to creation and deletion tasks, the WEB will also write Webhook Monitor events to the local dc#queue. If the WEB instance is running in data center 1 it will write to the dc1queue. When the bridge process identifies a Monitor event it will forward an event JSON message to the actions/broker.py process. Again, acting as a bridge between the web application and the back-end monitoring application.
Recovering from RethinkDB failures: when RethinkDB servers are experiencing issues, the RethinkDB instance may become read only until the other nodes are automatically recovered. During this time, Monitors and Reactions are unable to write historical logs of execution since the instance is read only. When the instance is read only, processes will write logs to Redis. When the bridge process is starting, it will read the Redis keys associated with these logs and process them and store this data into RethinkDB. This essentially becomes a write behind process.
Monitor creation process
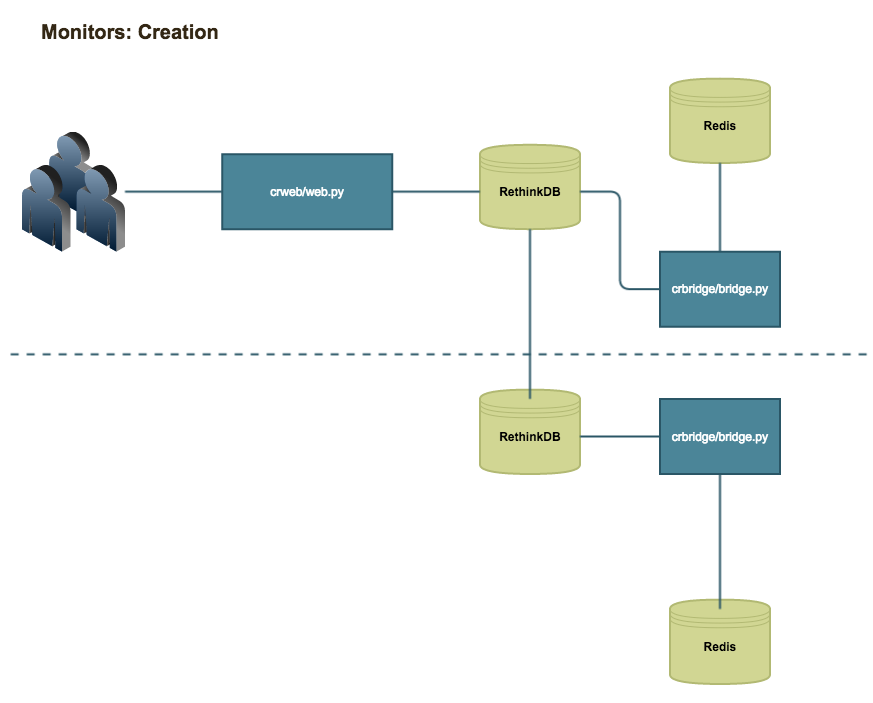
Reaction creation process

MONITORS - CloudRoutes Availability Monitor
The CloudRoutes Availability Monitor component is designed to perform the actual monitoring of remote systems. This is the monitoring part of the monitoring and reacting back-end application. This component is comprised of 3 major programs: control.py, broker.py, and worker.py.
Control
When the CloudRoutes Bridge process adds Monitor details into Redis, it looks at the Monitor details and extracts the interval value. This interval key is a queue. The Monitor's ID number is added to this queue which is essentially a sorted list within Redis. The interval defines how often the Monitors should be executed. In production today there are 4 valid intervals.
30mincheck: this sorted list is for Monitors that run every 30 minutes5mincheck: this sorted list is for Monitors that run every 5 minutes2mincheck: this sorted list is for Monitors that run every 2 minutes30seccheck: this sorted list is for Monitors that run every 30 seconds
The monitors/control.py program is a generic program that is designed to pull Monitor IDs from a defined sorted list in Redis (one of the intervals listed above). Once it has a list of Monitor IDs, it will loop through that list and look up the Monitor's details from Redis using the Monitor ID as a key. Once the Monitor's details are read, the monitors/control.py process will create a JSON message including the Monitor's details and send that message to monitors/broker.py using ZeroMQ.
Each monitors/control.py process can only read from one sorted list. In order to have all sorted lists monitored, each sorted list must have its own monitors/control.py process. This is possible because the monitors/control.py process receives all of its Redis and timer configuration from a configuration file. In production, there are currently 4 monitors/control.py processes running in each data center.
Broker
The monitors/broker.py or MONITORs Broker process is simply a ZeroMQ broker. The process binds two ports. One port is used to listen for ZeroMQ messages from the various monitors/control.py processes. The second port is used to send that received message to a monitors/worker.py process. In production, each data center currently has only 1 MONITORS Broker. However, this process is not limited to only one. When two servers are specified in an stunnel configuration, the stunnel service will send requests in a round robin algorithm. This allows the control messages to be sent to multiple brokers which then could be sent to multiple sets of workers.
Worker
The monitors/worker.py or MONITORs Worker process is the actual process that performs the Monitor tasks. The code to perform an actual Monitor check is stored as modules within the checks/ directory. For example, the TCP Port Monitor is the module checks/tcp-check. When the MONITORS worker process receives a health check message from the MONITORS Broker it decodes the JSON message and determines what type of check module should be loaded. It then loads the module and executes the check() function passing the Monitor-specific data to the function.
The check() function will return either True for true or False for false. With this result. the worker process will generate a JSON message which is then sent to the CloudRoutes Action Service.
Monitor execution process

The entire CloudRoutes Availability Monitor design is built to scale. The Worker processes are design to run in large numbers. In production, each monitoring zone is currently running approximately 25 worker processes. The Broker facilitates this, and by having each Control process route though the Broker we are able to fully utilize each worker process and able to distribute Monitor executions efficiently. The Control processes are the only singleton, but these processes are unique for each monitoring zone. It is simple enough to add monitoring zones as needed. If the performance of the Control process is unable to keep up with demand the answer is to simply add additional monitoring zones.
ACTIONS - CloudRoutes Action Service
The CloudRoutes Action Service or ACTIONS is designed to perform the "Reaction" aspect of Runbook's Monitoring and Reacting. Like the MONITORS there are two main programs with ACTIONS, actions/broker.py or ACTIONS Broker and actions/actioner.py or ACTIONS Actioner.
Broker
Like the MONITORS Broker the ACTIONS Broker simply receives JSON messages from the MONITORS Worker or BRIDGE Bridge processes and forwards them to a ACTIONS Actioner process. This facilitates the ability for multiple monitor results to be processed at the same time and from multiple machines. Similar to the MONITORS broker, this process is currently a single process in each data center although it does not necessarily require this. To scale the performance of Monitor result processing, multiple Brokers could be launched.
Actioner
The ACTIONS Actioner process is the process that performs Reaction tasks. Like the MONITORS worker, the code to perform a Reaction is stored within modules in the actions/ directory. An example of this would be the actions/enotify module which handles email notification Reactions.
When the ACTIONS Actioner process receives the JSON message from the MONITORS Worker process, it will first look-up the Monitor from Redis and then RethinkDB. If the RethinkDB request does not return a result due to a RethinkDB error, the Monitor is flagged as a cache-only Monitor. The idea behind this is that even if RethinkDB is down the Monitor should still be actioned to ensure that Runbook is providing its function of protecting user environments.
Each Monitor JSON message has a list of Reactions associated with that Monitor. After looking up the Monitor, the Actioner process will loop through these Reactions. The Actioner will look-up Reaction details first from Redis and secondly from RethinkDB, following the same process as the Monitor data look-ups. In this case, the Actioner will compare the lastrun time from both results and utilize the newest. This is to ensure that frequency settings within the Reaction are honored if the Reaction was executed from another data center.
When the Actioner process has the Reaction data it then loads the appropriate actions/ module and executes the appropriate method for performing the Reaction. When Reactions are executed, a set of "meta" Reactions are also executed. These "meta" Reactions are essentially Reactions of Reactions, and are used to update the RethinkDB and Redis datastores as well as update any Reaction-tracking logs.
After all user-defined Reactions have been executed, a list of default Reactions are executed for the Monitor. These Reactions are similar to the "meta" reactions, but are reacting on the Monitor itself rather than the Reaction.
Reaction execution

Architecture Diagrams
Below are links to Architecture Diagrams of the Runbook environment. Each of these diagrams show a different aspect of Runbook's application environment.
{kind=link}
This shows a holistic view of each component and its interactions. This also depicts a typical development environment setup. You can think of this as the minimal required implementation.
{kind=link}
This diagram depicts each component and its interactions as it is deployed in two data centers. When considering this deployment, it is feasible for Runbook to be deployed across more than two data centers.
{kind=link}
This diagram shows each component deployed in a highly scaled out and redundant design. Components with multiples can be scaled beyond the number depicted as needed. Components without multiples such as the control.py processes can expanded by adding additional monitoring zones. In theory, the BRIDGE Bridge component could support running multiple copies. However, this is untested at this time.